エージェントの可能性を広げるツール最適化: 文字列出力を中間表現にする
「LLMは基本的に文字列を出力するだけ」と聞くと、できることは会話や文章生成に限られるように感じます。ところが現実には、データ解析をしたり、PowerPointを生成したり、社内システムを操作したりと、出力が“行動”に変わっていきます。
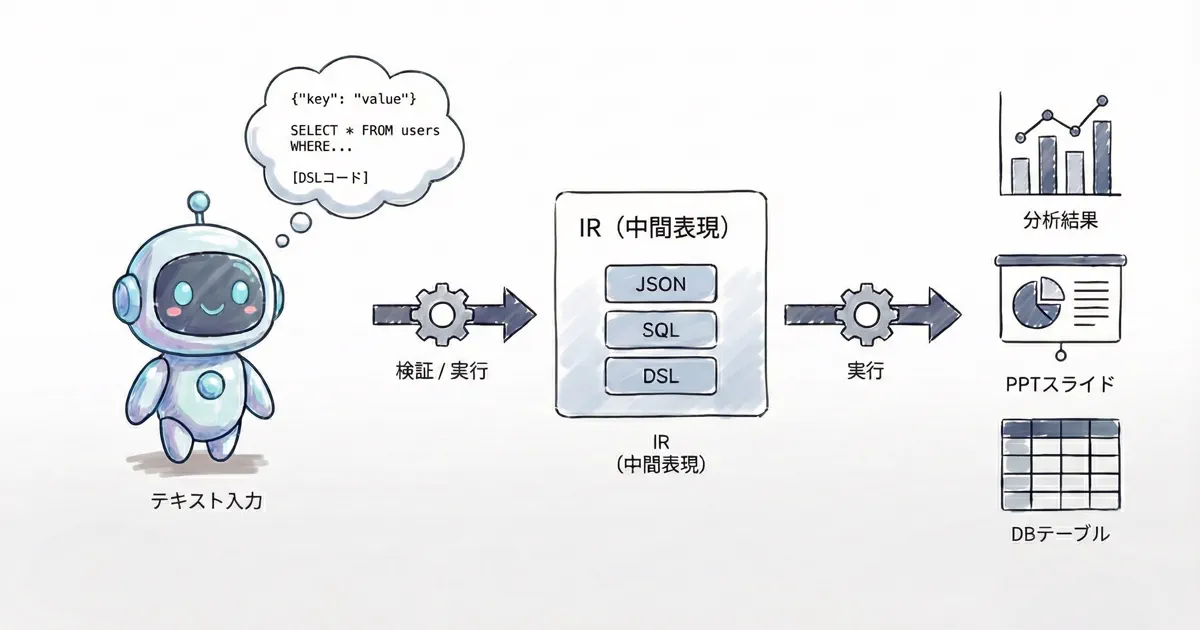
この記事では、なぜそんなことが起きるのかを「中間表現(IR)」という視点で整理します。要は、LLMの文字列を“そのまま成果物”として扱うのではなく、「後工程が実行できるルールベースの表現」に変換して渡しているだけです。SQLを書かせるのが強いのも、この構造が理由です。
そのうえで、エージェントの能力を引き出すためにツールをどう最適化するか、これから増えそうなツールの方向性、ツールを作るときの設計ポイントまでをまとめます。
要点#
LLMができることが急に増えたように見えるのは、LLMが賢くなったからだけではありません。文字列を「中間表現」にして機械に実行させる仕組みが整い、LLMがその中間表現を書く役割を担えるようになったからです。
ツール最適化の本質は、エージェントに「何をどう書けば実行できるか」を迷わせないことです。入出力を小さくし、形式を厳密にし、失敗したときに修正しやすいフィードバックを返す。すると、同じLLMでも安定して“仕事”になります。
LLMは「文字列を返す関数」でしかないのに#
まず前提として、LLMは多くの場面でテキスト(文字列)を返します。画像生成のような例外はありますが、少なくとも「業務を動かす」タイプのシステムでは、LLMは文字列を出し、周辺のソフトウェアがそれを解釈して次の処理につなげる、という形が中心です。
ここで重要なのは、文字列は最も互換性の高い入出力形式だということです。JSONやSQL、Markdownなど、現場のシステムは「ルールのある文字列」を介して接続されています。LLMはその“ルールのある文字列”を書くのが得意なので、結果として外部の道具を動かせるようになります。
この見方を採ると、「LLMがPowerPointを作る」という表現は正確ではありません。正確には「LLMがPowerPointを作るための仕様(中間表現)を書き、別のプログラムがPPTXを生成している」です。次のセクションで、この“中間表現”が何かをはっきりさせます。
文字列を中間表現にすると、出力は多種多様に#
ここでいう中間表現(IR: Intermediate Representation)は、実行器が解釈できる約束事(文法・制約)を持った文字列です。この記事では、中間表現を解釈して処理する側をまとめて「実行器」と呼びます。DBやコード実行環境、ファイル生成ツールなどです。
中間表現で表現できることが増えるほど、後段の実行器ができることの幅が広がります。結果として、LLMの出力は文章だけに閉じなくなります。
たとえばSQLは、現場で最も成功しやすい中間表現の一つです。短い文字列で「どのデータを、どう集計して、どんな形で返すか」を表現できます。しかも実行器(DB)が堅牢で、結果が表形式で返ってきます。LLMが“計算”を頑張らなくても、DBが計算してくれる。これが、SQLを書かせるアプローチが強い理由です。
もう一つ、表現力の意味では、プログラミング言語はある意味“最強の中間表現”です。 Pythonのような言語は「処理手順」そのものを表現できるので、実行器(ランタイム)さえあれば、集計・解析・可視化・ファイル生成までできます。いわゆる「データ分析」機能の多くは、LLMがPythonコードを書き、隔離された実行環境で走らせ、表やグラフやファイルとして結果を返す、という形で実現されることが多いです1。
同じ意味で、HTML/CSSも中間表現です。ブラウザという実行器があるので、文字列のままでも「表示仕様」として解釈され、レポートやLP、メールの雛形などに変換できます。文章生成に見えても、実務で価値が出る部分は「表示や構造の仕様」を作れているか、ということが多いです。
もう少し一般化すると、LLMが「中間表現を書く → 実行器が実行して結果を返す → LLMが結果を整形して返す」という分業が成立すれば、出力は「実行器が作れるもの」全てに広がります。グラフ、PDF、スライド、コード差分、チケット更新、メール送信など、どれも同じ構造です。
ただし中間表現が自由すぎると事故ります。次は、実際に“文字列が行動になる”ときに、裏側で何が起きているかを見ます。
ツール呼び出しは「中間表現→検証→実行→フィードバック」のループ#
エージェントがツールを使うとき、内部では次のような流れが回ります。ここまでが地図です。次は具体例に落とします。
まずは流れを手順として並べます。
- LLMが「必要なツール」と「引数」を出力する。多くの実装(例: OpenAI Agents SDK)ではJSONで表す(tool call / function calling)1
- 実行器が、出力がスキーマ(型・必須項目・制約)に合うかを検証する2
- 合っていればツールを実行する
- 実行結果をLLMに返し、次の呼び出しや最終回答に反映する
理想は、このサイクルを1回で終えて最終回答まで出すことです。必要なときだけ、検証エラーの修正や追加取得のためにもう一度回します。
このとき、ツール側が返すエラーも重要な入力です。パースに失敗した、必須項目が足りない、権限がない、タイムアウトした。こうした情報が“修正可能な形”で返れば、LLMは中間表現を書き直してやり直せます。逆に、曖昧なエラーや自由すぎる中間表現は、ループを壊しやすくなります。
PowerPointが作れる理由は「スライドの中間表現」を出しているから#
PowerPoint(.pptx)をLLMが直接出力しているわけではありません。多くの場合、LLMは次のような「スライド仕様」を中間表現として出力し、実行器(PPTX生成ツール)がそれをPPTXに変換します。
{
"title": "エージェントの可能性を広げるツール最適化",
"slides": [
{ "layout": "title", "title": "文字列→中間表現→実行", "subtitle": "LLMが出すのは基本的に文字列" },
{ "layout": "bullets", "title": "なぜ実現できるか", "bullets": ["中間表現がルールを持つ", "実行器がリッチな成果物を生成する"] }
]
}この仕様はJSONでもYAMLでも独自DSLでも構いません。重要なのは、実行器が解釈でき、LLMが安定して書けることです。
PPTXの場合、実行器は python-pptx3 のようなライブラリで、slides.add_slide() でスライドを追加しながらPPTXを組み立て、ファイルとして返します。
OpenAI Agents SDKでも、関数ツールの戻り値としてテキストだけでなくファイルや画像を返せる、と明記されています1。チャットUIが「添付ファイル」として見せているのは、LLMの文字列ではなく、この実行器の成果物です。
ここまでを見ると、ツールの価値は「LLMに何をさせるか」よりも「中間表現と実行器をどう設計するか」に寄っていることが分かります。次は、その設計を最適化するポイントに絞ります。
ツール最適化のポイント: 中間表現を“書きやすく、壊れにくく”する#
ツールを最適化するときの狙いは、エージェントの賢さを上げることではありません。同じLLMでも、迷いにくく、失敗しても立て直せる道具にすることです。
1. 中間表現は「既製品」を優先し、自由度を絞る#
まず中間表現は、可能な限り既製の規格を使います。SQL、JSON、Markdownなどは、周辺ツールが成熟していて検証もしやすいからです。独自DSLは、表現力が必要なときだけにします。自由度が高いほど、LLMは“それっぽいが解釈できない文字列”を出しやすくなります。
SQLを使うなら「読み取り専用のSELECTだけを許可する」「タイムレンジやLIMITを強制する」のように、実行器側で制約を持たせます。JSONならJSON Schema2で必須項目と型を固定し、列挙(enum)で選択肢を絞ります。採用するなら、実行器側で対応するドラフトを固定しておくと事故が減ります。ポイントは、LLMの自由を増やすのではなく、成功する形を狭く決めることです。
2. 入出力を小さくして、1回で完結する形に寄せる#
ここでの「1回」は理想です。検証エラーの修正や追加取得が必要なら、ループして構いません。
エージェントが不安定になる典型は「巨大な文脈」と「曖昧な命令」です。ツール側の入出力は、できるだけ小さくします。たとえば解析なら「生ログ全文」を渡すのではなく、「期間・指標・粒度」を引数にして集計結果だけを返すほうが安定します。
言い換えると、ツールは“重い処理を背負う”ほうが良いです。LLMは判断と合成に寄せ、計算・探索・変換は実行器に寄せる。ここが分業の基本です。
3. 失敗時の戻り値を「修正可能」にする#
ツールが失敗したときに「エラーです」だけ返すと、LLMは何を直せばよいか分かりません。スキーマ違反なら「どのフィールドが」「なぜ」ダメかを返す。
たとえば title が必須(required)なのに欠けているときは、次のように返す。
{
"error": "invalid_arguments",
"issues": [{ "path": "$.title", "keyword": "required", "message": "必須です" }]
}SQLなら「禁止構文」「テーブル名の候補」「LIMITがない」など、修正の方向が分かる情報を返す。こうすると、ループが回りやすくなります。
この設計は、エージェントの性能というより“デバッグ体験”です。人間が直せるエラーは、LLMも直せます。
4. 安全性は「実行器の制約」で担保する#
中間表現を実行する以上、必ず境界が生まれます。だからこそ、セキュリティはプロンプトではなく実行器側で担保します。DBは読み取り専用の接続にする、更新系APIは人間の承認を挟む、外部アクセスはドメイン許可リストにする。これらはLLMの“善意”に依存しない設計です。
また、ツールの返り値に「次はこれをしろ」という指示が混ざることもあります。たとえばOpenAI Model Specでは、ツール出力や引用されたテキストは「信頼できないデータ」として扱い、そこに含まれる指示は“情報”として扱う、という前提を置いています4。
これから増えそうなツールの方向性#
最後に、今回の主題である 中間表現で何が表現できるか を、ビジネスの現場で刺さる形に棚卸しします。ここでは「これから増えそうなツール」を技術トレンドとして当てに行きません。
ポイントは、成果物そのものではなく「成果物を作るための仕様」を中間表現として持てるかどうかです。仕様を一度作れれば、同じ仕様から別の実行器に流すだけで出力を増やせます。
たとえば次のような「仕様」を中間表現にできます。どれも形式は JSON や YAML、あるいは SQL のような既製のルールで十分で、重要なのは 何を表現するか です。
- 指標・レポート仕様: KPI、期間、粒度、セグメント、注釈などを表す。
SQLやBIのクエリに落ちるだけでなく、週次のSlack投稿、月次の役員会スライド、異常検知アラートまで出力が広がる。 - 資料仕様(スライド仕様): 章立て、1枚ごとの目的、図表、話す順番を表す。PPTXだけでなく、1枚サマリ版、詳細版、読み上げ原稿、英語版の生成に展開できる。
- ソフトウェア仕様(コード/テンプレート): PythonやTypeScript、HTML/CSSなどで「処理」や「表示」を表す。解析の自動化、社内ツール、LP/レポート生成など、実行器次第で出力が広がる。
- タスク仕様: 目的、担当、期限、完了条件、依存関係、リスクを表す。起票だけでなく、会議設定、リマインド、進捗レポートの自動化につながる。
- 承認・チェック仕様: 承認点、条件、例外、証跡を表す。稟議フロー、監査ログ、差し戻し理由の定型化など、運用そのものを整形できる。
- 提案・見積仕様: 目的、範囲、成果物、制約、体制、期間、前提を表す。提案書だけでなく、見積書、SOW、WBS、リスク登録簿などに展開できる。
- 顧客リスト/施策仕様: 対象条件、除外条件、訴求、チャネル、タイミングを表す。配信だけでなく、A/B設計、結果集計、次アクション提案までつながる。
- 変更仕様(差分/パッチ): 「何をどう変えるか」を表す。丸ごと生成よりレビューしやすく、適用と巻き戻しを運用に乗せやすい。
差分の中間表現としてはJSON Patch(RFC 6902)が代表例で、add / remove / replace などの操作を配列で並べて表現します5。
この棚卸しが示すのは、「LLMが賢いからできる」というより、ルール化された仕様を受け取って実行できる実行器があるからできる ということです。
ここから先で広がりやすいのは、「成果物の仕様」よりも 手順・制約・責任分界を含む仕様 です。たとえば「実行計画(何を、どの順で、どこまで)」を中間表現にし、前提条件・影響範囲・ロールバック・承認点を明示できると、同じ自律でも現場に通しやすくなります。これができる中間表現は、見た目は地味でも「安全に任せられる範囲」を大きくできます。
そして予測(可能性)としては、この“表現力が高い中間表現”が一般化するほど、そこから出せる出力は直感よりずっと増えます。
たとえば「指標・レポート仕様」が標準化されると、単にダッシュボードを作るだけで終わりません。指標の定義に紐づいた SQL、データ品質テスト、異常検知、役員会向けの要約、現場向けの改善タスクまで、一つの仕様から一貫して生成・運用できるようになります。
同じように「提案・見積仕様」が標準化されると、提案書に加えて、見積の内訳、契約の付属資料、プロジェクト計画、進捗の観測指標までが“仕様から派生”する形になっていきます。
中間表現そのものは短いのに、実行器の組み合わせで“想像以上の出力”が出る、という状態です。
まとめ#
LLMが解析やスライド生成までできるように見えるのは、文字列を中間表現として扱い、実行器がリッチな成果物を作っているからです。SQLを書かせるのが強いのも同じ理由で、短い中間表現で大きな処理を委譲できます。
ツールを最適化するときは、中間表現を既製品で固め、入出力を小さくし、検証とエラーを修正可能にし、安全性を実行器の制約で担保します。そうすると、同じLLMでも迷いにくくなり、エージェントの“可能性”が素直に広がります。