AIエージェントの基礎: ワークフローから自律まで
「AIエージェント」という言葉の定義は、少しずつ揃い始めています。OpenAI Agents SDKは「instructionsとtoolsを設定したLLM」と説明し1、Vercel AI SDKは「ツールをループで使ってタスクを達成するLLM」と定義しています2。共通するのは、LLMがtool call(関数呼び出しに類する仕組み)でツールを使い、その結果をフィードバックに次の一手を決める、という構造です。
とはいえ現場でまず迷うのは「エージェントを作るか」ではなく、「ワークフローにするか、エージェントにするか」の選択です。ワークフローは決まった動きに強く、品質とコストが安定しやすい一方で、決まったことしかできません。エージェントは探索や例外に強く、状況に応じて手順を組み替えられますが、自由度が高いぶん寄り道しやすく、無駄なツール呼び出しが増えがちです。この選択は「ワークフローは簡単だから」では決まりません。タスクによっては、エージェントのほうが実装も運用も単純なこともあります。
設計としては instruction / tool / user input の3要素で捉えると、議論が噛み合いやすくなります。この記事では、この3要素を軸に、ワークフローとエージェントの使い分けから、実装・運用で押さえるべきポイントまでを整理します。
要点#
この記事でいうAIエージェントは、LLMがtool callでツールを呼び出し、結果のフィードバックで次の一手を決める仕組みです。設計は instruction / tool / user input の3要素に分解できます。
ワークフローとエージェントの選択は、特性で決めます。決まった操作と大量データの処理はワークフローが強く、探索や例外対応はエージェントが強いです。とくに tool は"できること"の上限とリスクを決める要素なので、最小のツールを作り、説明を厚くして迷わせないのが近道です。巨大な情報をそのままLLMに読ませるより、検索や集計のように「小さな入出力で大きな処理をできるツール」を先に設計すると、精度とコストが安定します。
運用では停止条件・承認・ガードレール・観測(トレーシング)を先に入れ、無駄なループとコストを抑えます。
ワークフローとエージェント#
Anthropicは「AIエージェント」という言葉の多義性を整理し、事前定義のコードパスでLLMとツールを組み合わせるワークフローと、LLMが自律的にプロセスやツール使用を指揮するエージェントを区別しています3。この違いは再現性・検証可能性・コストに直結するため、最初に言葉を揃えておくのが近道です。
ワークフローは手順が固定されたLLM連携であり、品質とコストが安定しやすい構造です。コンテキストウィンドウに載らない量の情報を扱う場面でも、前処理(検索・集計・要約など)で「載る形」にしてからLLMに渡せます。一方エージェントは、LLMが動的にツールを選び進め方を決める仕組みで、状況に応じて手順を組み替えられます。
どちらを選ぶかは「簡単そうか」ではなく、操作がどれだけ固定か、扱う情報量がどれだけ大きいか、探索や例外がどれだけ多いかで決めるのが安定します。現場では「ワークフロー=簡単」「エージェント=難しい」とは限りません。タスクによってはエージェントのほうが素直で、実装が短く済むこともあります。
コンテキストウィンドウはモデルごとにトークン上限として仕様が決まっており、この上限はここ数年で増え続けています。固定の数字に縛られすぎると古い議論になりますが、無限ではないので「LLMに何を見せるか」の設計は今も重要です。
3つの設計要素#
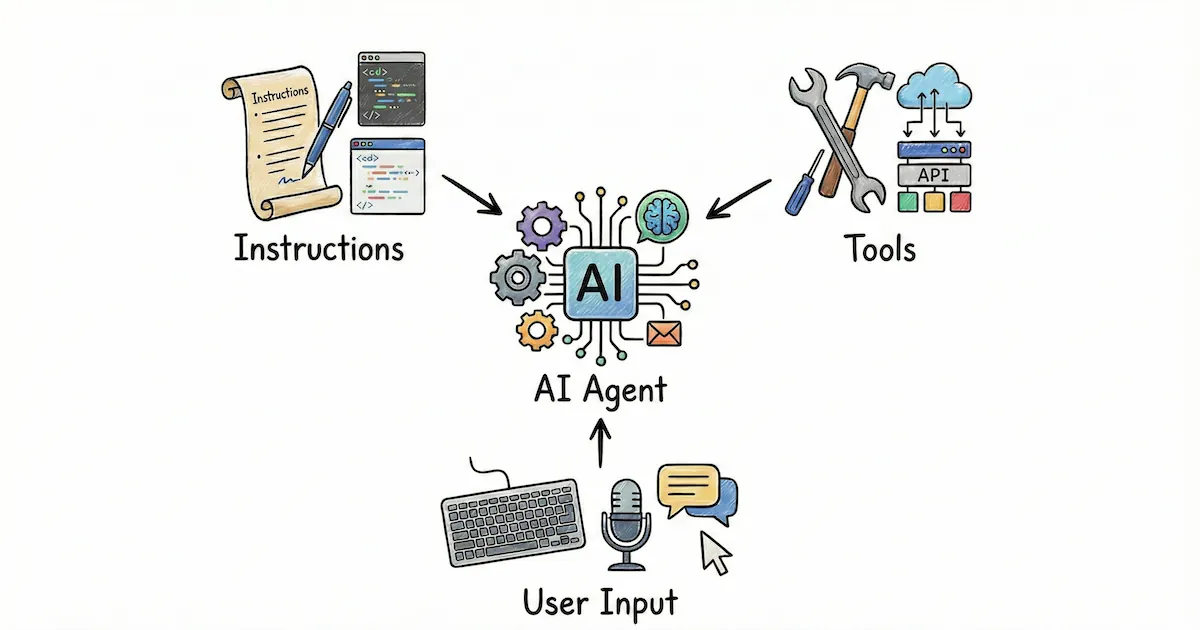
エージェントを設計するとき、複雑に見えても改善はだいたい3つの要素に集約できます。instruction(指示)は役割・制約・ゴール・判断軸・出力形式を決め、tool(道具)は取得できる情報と実行できる行動を決め、user input(入力)はその場の状況・素材・追加コンテキストを入れます。この3つのバランスを変えるだけでエージェントはかなり別物になるので、複雑なアーキテクチャより「どのつまみを回すか」をはっきりさせるのが近道です。
instructionは判断の基準を渡す場所です。 OpenAI Agents SDKでは instructions をdeveloper message / system promptとして扱い、モデルの役割や制約を定義しています。ここが曖昧だと、後からツールを足しても方向性がブレやすくなります。実務で効くのは、成功条件(どこまでできたらOKか)、禁止事項(絶対にやらないこと)、出力の形式(箇条書き、JSON、表など)の3点です。この3点が揃うと、後から tool や user input を増やしてもブレにくくなります。
toolはできることの上限が決まる場所であり、同時に事故が起きやすい場所でもあります。 OpenAI Agents SDKのToolsはデータ取得、コード実行、外部API呼び出し、コンピュータ操作などをエージェントが行動する仕組みとして提供しています。Anthropicはツールセットとドキュメント設計が重要だと強調しており3、Vercel AI SDKはツールを description / inputSchema / execute の3要素で定義し、schemaがツール呼び出しの検証にも使われます。ツールは増やせば強くなりますが、説明が曖昧だと逆に弱くなります。ツールの価値は「数」ではなく「迷わせない説明」と「事故らない引数設計」で決まります。
もう一つ重要なのは、入出力を小さく保ちながら大きな情報を扱えるかどうかです。巨大な情報をそのままLLMに読ませることもできますが、たとえば検索ツールで質問に関係する断片だけ返す、解析ツールでExcelのSUM関数のように小さな入力で大きなデータを処理し短い結果だけ返す、といった設計が精度とコストの両面で効きます。さらに、ツールを「作る」だけでなく「つなぐ」ことが本番の壁になります。MCP(Model Context Protocol)はAIアプリを外部システムに接続する標準として、USB-Cの比喩で説明されています4。社内のデータや業務操作に安全に・一貫して接続できる入口を用意することが、実務では一番効きます。
user inputはユーザーが書く入力だけでなく、システム側で補う入力も含めて考えます。 ユーザーの入力だけをそのまま渡すと、前提が欠けていて失敗しがちです。OpenAI Agents SDKは、追加データをLLMに渡す方法として、instructionsに恒常的な情報を足す、inputに追加メッセージとして足す、ツールでオンデマンドに取得する、retrieval/web searchで根拠を引く、といった選択肢を挙げています。Vercel AI SDKはエージェントループの各ステップ前に prepareStep でメッセージやツールを差し替えられ、「最初に社内規約を短く注入する」「ツール結果を要約してから次ステップへ進める」といった入力の自動整形が実装しやすくなっています。ユーザーに頑張って書かせるのではなく、システム側で不足を補い読みやすい形に整えるのが安定します。
ループと運用#
Vercel AI SDKはAgentsを「ツールをループで使ってタスク達成するLLM」と定義し、ループの要素としてcontext managementとstopping conditionsを挙げています2。Anthropicも停止条件(最大反復回数など)で制御し、必要なら途中で人に戻すことを推奨しています。自律性が上がるほどループは強くなるので、いつ止めるか(回数・時間・コスト)とどこで人に戻すか(承認ポイント)は最初に決めておくと安心です。止め方が決まって、はじめて自律度を上げられます。
運用に入ると「賢さ」より「壊れ方」が重要になります。OpenAI Agents SDKのGuardrailsは入力/出力の検証と、並列実行・ブロッキング実行(コスト最適化や副作用回避)の考え方を提示しています。Tracingは、LLM生成・ツール呼び出し・ハンドオフ・ガードレールなどのイベントを記録し、開発から本番でのデバッグ/監視に使えます。観測できる状態にしておくと、失敗の原因が追えて改善が速くなります。
実践の進め方#
実務で「つまずきにくい順番」で進めるなら、まずワークフローかエージェントかを選ぶところから始めます。ここでやりたいのは「エージェントを採用する」ことではなく、目的のタスクを最短で安定させることです。決まった操作を高い精度で繰り返したい、あるいは扱う情報量が大きく前処理で圧縮してからLLMに渡したいならワークフロー向き。手順が固定できず環境からのフィードバックで進め方が変わるならエージェント向きです。どちらであっても、LLMが処理するのはコンテキストに載る範囲だけなので、ワークフローなら前処理で圧縮し、エージェントならツールで必要な断片だけを返す設計になります。
方向性が決まったら、次はinstructionから固めます。まず目的と成功条件を固定し(入力、出力、許容誤差、失敗時の扱い)、次に不明点の扱いを決め(質問してから進めるか、仮置きして進めるか)、最後に出力の形式を決めます(読む人の手戻りが減る形式に揃える)。この3点だけ先に固定すると、以降のtool / user inputの設計が軽くなります。
ツール設計では「小さく・安全に・迷わせない」を意識します。まず読み取り系(検索、DB参照、FAQ参照など副作用の少ないツール)から始め、次に更新系は承認を挟みます。OpenAI Agents SDKのMCPドキュメントでは、機微なツールに対して require_approval を設定し、人/プログラムで承認してから実行できます。ツールの説明は「ドキュメント」として書き、Anthropicは例・境界・エッジケースの記載やpoka-yoke(ミスしにくい引数設計)を提案しています。「何ができるか」より先に「何をさせないか」を決めておくと、運用が壊れにくくなります。
user inputは必要なら自動で足してよい領域です。ユーザーの所属/権限、対象期間、プロジェクトIDなどの前提を先に注入し、参照すべき社内ドキュメントをretrievalで引き、長い履歴やツール結果は要約して文脈量を管理します。入力が整うと、モデルの出力は驚くほど安定します。
ここまで来たら、暴走させない工夫を入れておきます。最大ステップ数、タイムアウト、コスト上限で止め、段階的にツールを解放し(検索→分析→更新)、途中のチェックポイントで人に戻します。ループは「回す」前に「止める」を決めておくのがコツです。
最後に運用の土台として、ガードレールと観測を入れます。運用を前提にするなら、最後に足すより最初に入れる方が楽です。入力ガード(悪用・逸脱・意図不明)と出力ガード(機密、誤情報、形式逸脱)を設け、トレーシングで「どのツールをいつ呼んだか」「どこで失敗したか」を追える状態にします。ここまでで、最小の本番運用に必要な骨組みが揃います。
注意点と工夫#
ここまでの手順で形にはできますが、現場で効かせるには落とし穴も把握しておきたいところです。自律度が上がるほどレイテンシとコストは増えます。フレームワークは便利ですが、抽象化が増えるとデバッグが難しくなります(Anthropicも指摘3)。ツール実行には権限制御や隔離環境が必要で、設計を後回しにできません。
実務で効きやすい工夫を2つ挙げます。どちらも「エージェントを賢くする」というより「迷わせない・事故らせない」ための工夫です。
まず、ツールは「作る」より「つなぐ」ことが本番の壁になります。ツールが増えると接続先(ファイル、DB、SaaS、社内API)も増え、個別実装が乱立しやすくなります。MCPで接続を標準化すると、この問題を避けやすくなります。エージェントの価値は「会話」よりも「業務の入口に安全に触れる」部分で出ます。
もう一つはプロンプトインジェクションへの対策です。ツールやコンテキストを増やすほど「境界」は増えます。OpenAI Model Specは、指示の優先順位をRoot > System > Developer > User > Guidelineの順で定義し、ツール出力は原則「No Authority(権限なし)」として扱う前提を明記しています5。実務では「社内ドキュメントを読ませたら変な指示が混ざっていた」が起きるので、データと指示を分けて扱う設計が必要です。
活用事例#
AnthropicやVercelのドキュメントで紹介されている活用事例を見ると、共通点は会話だけでなく行動(ツール実行)が必要なことです。
カスタマーサポートはAnthropicが有望な領域として整理しています。サポートは「会話」と「行動(ツールによる情報取得・払い戻し・チケット更新など)」を両立し、成功条件(解決)が測りやすい点がエージェント向きです。Vercelも社内例としてサポートエージェントがチケットを3分の1削減したと紹介しています。
コーディングエージェントはテストで検証でき、フィードバックループを回しやすい点でエージェントに向くとAnthropicは説明しています。Claude Agent SDK overviewでは、ファイル読み取り・コマンド実行・Web検索・コード編集などを自律的に行うエージェントをライブラリとして構築できると述べています。
調査・レポートではClaude Agent SDK demosに、サブエージェントを並列に走らせて調査→統合レポートを作るResearch Agentのデモが含まれています(ローカル開発向けデモと明記)。
社内の自動化ではVercelがサポートだけでなく「業務の片付け」にエージェントを使っている例を紹介しています。セキュリティチームが高リスクURLを解析して推奨アクションを返すエージェントや、コンテンツチームがSlackスレッドから記事ドラフトを作るエージェントなどです。このタイプは user input を自動で増やす(スレッドの要約、関連リンクの取得など)工夫が効きやすいです。
haya株式会社としての支援#
ここまでの例を見ると、エージェントはとても万能に見えます。ですが企業の現場では、データの所在、権限、既存システム、責任分界が必ず出てきます。だからこそ「instruction/tool/user inputをどう設計し、どう安全に運用するか」まで含めて、一緒に組み立てる必要があります。
haya株式会社では、業務分解から本番導入・運用定着までを一気通貫で支援しています。現場の暗黙知をほどいて instruction/tool/user input に落とし込み、回る形にするのが役割です。進め方としては、まず業務分解で判断点・知識依存・例外を整理しAI化できる単位に分解します。次にAI適用設計で instruction/tool/user input を中心にLLM/RAG/データ構造と評価指標を定義します。そして実装・統合で既存システム連携、権限設計、ガードレール、観測を含めて実装し、最後に定着・改善として運用フローに組み込み改善サイクルまで設計します。
「どこまで自律にするか」「更新系ツールをどう安全に扱うか」など、境界条件の整理から一緒に進められます。
まとめ#
AIエージェントは「最初から自律(自由度最大)」にするものではありません。ワークフローとエージェントを特性で選び、必要な範囲だけ自律度を上げるのが現実解です。まずは一つの業務フローを選び、instruction/tool/user input の3要素を小さく回して、再現性と運用コストを確かめてみてください。迷う点があれば、状況を一緒に整理しながら進めるのが近道です。